These programs follow the same copyright as LIBSVM. I do not take any responsibility on damage or other problems caused by using these programs. But you are welcomed to discuss with me if you have difficulty applying them for your needs.
The program performs ordinal regression with SVM using two different formulations. The first one comes from a reduction method to a regular binary SVM. The second one implements the SVORIM algorithm of Chu and Keerthi, which is another instance of reduction. Details about the reduction method, as well as comparison between two formulations, can be found in
L. Li and H.-T. Lin. Ordinal Regression by Extended Binary Classification, 2006.
The latest implementation is modified from LIBSVM 2.81 in October 2006. You can download the source code here.
The program performs alpha seeding as a heuristic to speedup SVM training, which is usually helpful when the kernel matrix is of low rank (e.g. linear with a small number of features). See "Decomposition Methods for Linear Support Vector Machines" by Kao et al. for some discussions.
The program uses my own trick to update the gradient when alpha is multiplied by some ratio, which can be applied to any kernels. The latest implementation is modified from LIBSVM 2.81 in March 2006. Please download the source code here. Only svm.cpp is changed.
The program trains different examples with different relative weights (Ci = C * Wi). It currently supports C-SVC and EPSILON-SVR, with both C/C++ and Python routines.
The latest implementation is modified from LIBSVM 2.81 in December 2005. It follows some previous work of Ming-Wei Chang in LIBSVM-Tools. Please download the source code here or in LIBSVM-Tools, and start from the README file.
The program computes the raw decision value or the confidence margin (which considers whether the decision value agrees with the binary label) outputed by a binary SVM. A previous version of the program was used for the paper:
L. Li, A. Pratap, H.-T. Lin and Y. S. Abu-Mostafa. Improving Generalization by Data Categorization, 2005.
The latest implementation is modified from LIBSVM 2.8 in May 2005. You can download the source code here or check our methods for data categorization here.
The program provides SVM with stump kernel, perceptron kernel, Laplacian kernel, and exponential kernel, which are first discussed in my Master's thesis from an ensemble point-of-view:
H.-T. Lin. Infinite Ensemble Learning with Support Vector Machines, 2005.
The experimental results show that stump kernel and perceptron kernel could have similar performance to the popular Gaussian kernel, but they enjoy the advantage of faster parameter selection. Please check our JMLR '08 paper for details.
The latest implementation is modified from LIBSVM 2.8 in April 2005. You can download the source code here.
The programs compute posterior probability from SVM outputs using the method of J. Platt. They implement an improved algorithm studied in the paper:
H.-T. Lin, C.-J. Lin, and R. C. Weng. A Note on Platt's Probabilistic Outputs for Support Vector Machines, 2003.
The routines follow the pseudo code in the paper. They are written in May 2003. You can check the MATLAB implementation here, the Python implementation here, or the C implementation in LIBSVM 2.6+.
Note that there is now a package with native dense format implementation in LIBSVM-Tools. The program below only includes a wrapper-style implementation, and may not be as efficient as the native one.
The program adds the ability to read dense format files for svm-train and svm-predict in LIBSVM. Note that the internal structure of LIBSVM is not changed. In addition, two python scripts, dense2sparse.py and sparse2dense.py, are included for easy transformation between sparse and dense formats.
The latest implementation is modified from LIBSVM 2.84 in August 2007. You can download the source code here. Previous implementation based on LIBSVM 2.81 in April 2006 is here.
The program computes the leave-one-out error by LIBSVM, and demonstrates how to do decremental training efficiently.
The initial implementation was done with LIBSVM 2.4. The latest implementation is modified from LIBSVM 2.84 in September 2007. You can download the source code here.
The program adds the ability to do repeated cross validation (CV) in LIBSVM. If the CV process is repeated for T times, given by the option -x T in training, the variance of the CV result would decrease with T. The feature helps to perform parameter selection in a more stable manner, with the price of more computation.
The initial implementation was done before the release of LIBSVM 2.7, and was used to compare with stratified CV. The latest implementation is modified from LIBSVM 2.81 in October 2006. You can download the source code here. Only svm-train.c is modified.
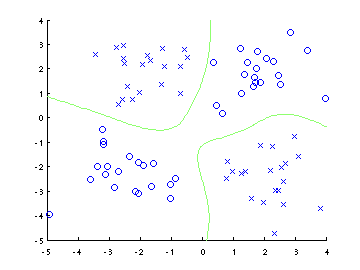
The program is similar to svm-toy in LIBSVM. It can be used to visually show the results of SVM. It works by obtaining the SVM decision values on the 2-D plane, and draw the contour of the values. The default setting, as shown below, is for binary classification.
The program works with the matlab interface of LIBSVM 2.7+. You can also use the program to show the results of regression or one-class SVM, with a few lines of modification. The initial implementation is done in March 2005, and the latest version is modified in November 2007. Please download svmtoy.m here.
Feel free to contact me: "htlin" at "csie.ntu.edu.tw"